完整代码:https://github.com/rosedblabs/rust-practice/tree/main/mvcc
事务及 MVCC
数据库的事务是一个经久不衰的话题,相信大家都已经耳熟能详了,事务是指数据库中单一逻辑工作单元的操作集合。这些操作要么全部成功执行,要么全部失败,从而确保数据库的一致性和完整性。
事务有 ACID 四个特性,分别是:
- 原子性(Atomicity):事务应该被视为不可分割的最小执行单元。这意味着事务中的所有操作要么全部完成,要么全部失败回滚。如果事务中的任何一部分操作失败,整个事务将会被回滚到初始状态,不会留下部分执行的结果。
- 一致性(Consistency):事务在执行前后,数据库应该保持一致性状态,不会破坏数据库的完整性。
- 隔离性(Isolation):事务的执行应该相互隔离,使得每个事务感觉自己在操作数据库时是独立的。这意味着并发执行的事务之间不应该相互影响,即使它们同时访问相同的数据。这样可以防止并发执行时出现数据不一致或者丢失的问题。
- 持久性(Durability):一旦事务被提交,其结果应该是永久性的。即使系统崩溃或发生故障,已经提交的事务所做的改变也应该被永久保存在数据库中,不会丢失。
其中原子性一般是通过预写日志来保证,持久性是通过预写日志和存储管理完成,隔离性常用的方式有多版本并发控制(MVCC)、两阶段锁等等。
隔离性是这其中稍微复杂的,其他的几个特性其实都不难理解,这篇文章将会使用 Rust 代码,实现一个最基础的 MVCC 事务,让一些重要概念不仅仅存在于理论层面,而是让大家上手实践,这样才能够加深理解并完全掌握。
我们知道数据库的隔离性其实又分为了四种,分别是
- 读未提交(Read Uncommitted)
- 读提交(Read Committed)
- 可重复读(Repeatable Read)
- 串行化(Serializable)
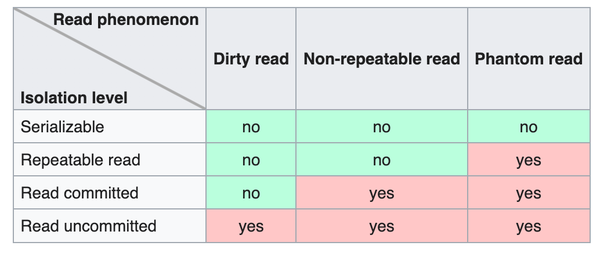
总体来说 MVCC 是实现事务隔离性的手段,通过 MVCC 可以很方便的实现可重复读。
MVCC 是建立在数据多版本的基础之上的,当写入一条数据的时候,会带上一个版本号,这个版本号一般是事务的唯一标识,修改数据的时候,不会直接原地去修改数据,而是新增一条新的数据,并且带上一个新的版本号。
这样一条数据实际上就会在物理存储上存在多个版本,当读取数据的时候,会找到第一个满足条件的数据并返回。
这样的好处是:读不会阻塞写,写也不会阻塞读, 最大限度提升了数据库的并发性能。
如下所示,横轴表示数据库中的 key,竖轴表示事务开始的时间顺序。
| |
事务 T2 启动的时候,它看到的值是 a=a1,c=c1,d=d1。
随后又有几个事务修改了 a(将 a1 改为 a4),新增了 b=b3,并且删除了 d。
这时候事务 T5 开始,它看到的值是 a=a4,b=b3,c=c1。
可以看到对数据的修改并不是原地的,而是新增加一个版本的数据,删除数据的时候,其实也不是真正的将其删除掉,而是通过标记的方式。
接下来通过具体的代码来进行更进一步的了解。
需要说明的是,出于演示的便利性,代码全部使用了基于内存的数据结构,所以严格意义上来说并不满足事务的原子性、持久性,但这并不妨碍我们去理解 MVCC 的精髓。
事务定义
事务的定义使用一个单独的结构体来表示,分别包含了存储数据的底层 KV,事务的版本号,以及活跃事务列表。
active_xid 是一个事务私有的数据结构,保存了在这个事务启动时,其他活跃的(未提交)事务集合,这是实现可重复读的关键,保证就算其他事务提交了,也不会影响到当前的事务。
| |
再来看一下事务的具体操作。
开启事务
首先是开启事务,这里是申请一个全局唯一的事务版本号,并且保存当前活跃事务列表。
| |
写入数据
然后是写入数据,需要判断当前写入的 key 是否和其他的事务发生了冲突,如果是的话,则需要返回错误,通知调用者进行重试。
这里判断冲突主要的逻辑是扫描最后一个 key 及其对应的版本,并判断其可见性:
- 如果最后一个 key 可见,说明是当前事务自己写入的,或者是比自己更早的已经提交的事务的写入的,可见。
- 如果 key 的版本号存在于活跃事务列表中(其他事务修改了,并且没提交),或者版本号比自身大(有新的事务修改了数据并提交),说明存在并发写入冲突。
如果没有冲突,则写入数据,也分为了两个步骤,一是记录了当前 version 写入了哪些 key(主要保证回滚时可以将数据删除掉),二是实际向存储引擎写入对应的数据。
| |
可以看到写入数据的时候,需要将原始的 key 加上当前版本号。
提交事务
提交事务的逻辑比较简单,因为所有需要写入的数据实际上都已经写入完成了,这时候只需要将这个事务的版本号从全局的活跃事务列表中删除就可以了。
| |
这样后续新开启的事务可以看到这个事务的修改,而其他未提交的事务,仍然看不到这个事务的修改。
回滚事务
回滚事务的逻辑和提交事务有些类似,唯一的区别是,需要将写入的数据重新删除掉。
这样做的目的是确保事务的一致性,因为事务回滚之后,原来已经写入的数据不能对后续的事务可见,所以需要全部删除掉。
| |
读取数据
读取数据的逻辑比较简单,因为数据 key 是按照 version 排序的,所以只需要从后往前遍历,找到第一个可见的记录,就是当前事务能够得到的对应 key 的结果。
需要说明的是,这里的处理逻辑稍微有点冗余,因为直接遍历了整个 map 去查找对应的 key,但实际上因为我们写入的 key 都是有序的,所以只需要前缀遍历即可。
| |
总结
MVCC 的核心是“多版本”,即同一个 key 在写入、更新、查询的时候,都会和当前版本号相关,通过事务的版本号来判断数据的可见性。
并且存储的时候,同一个 key 在物理上会有多份,分别对应不同的版本,本质上是一种通过空间冗余的方式来提升并发性能,让每一个事务都“看起来像”是单独执行,不受其他并发事务的影响,做到了读写互不阻塞。
通过上面的理论知识讲解和代码实战,相信你能够对 MVCC 理论有了一个更加深入的理解了。
完整代码地址:https://github.com/rosedblabs/rust-practice/tree/main/mvcc