前面提到了 Postgres 中的数据文件是被换分为了多个 page,每个 page 的大小默认是 8 KB。当我们向表中插入数据的时候,就需要从这些 page 中找到一个能够放得下这条数据的 page。
因为数据文件 page 的组织是无序的,元组的插入也是无序的,所以如果依次遍历查找满足条件的 page,可能会非常的低效,Postgres 中使用 FSM(Free Space Map) 来进行查找,加速找到适合插入的 page 的过程。
FSM(Free Space Map),即空闲空间映射,其目的主要是快速定位一个有足够空间容纳插入元组的文件页。
我们需要保证这个映射空间尽可能小,并且辅以一个高效的数据组织方式,这样才能够快速的检索。
在 Postgres 中,一个 page 默认的大小是 8KB,默认情况下一个文件的大小是 1GB,所以能够最多容纳 131072 个 page。
如果我们采用一个 32 位 int 类型来表示一个 page 的空闲空间的话,当然是没问题的。但是如果 page 很多的话,每个 page 都需要 32 位来表示空闲空间的值。
FSM 也是需要物理存储的,为了在搜索的时候,能够更加快速,我们需要保证 FSM 占用的空间尽可能的少,所以在 Postgres 中采用了分类别的方式,将空闲空间的大小以 32 为步长,分为了 256 个区间:
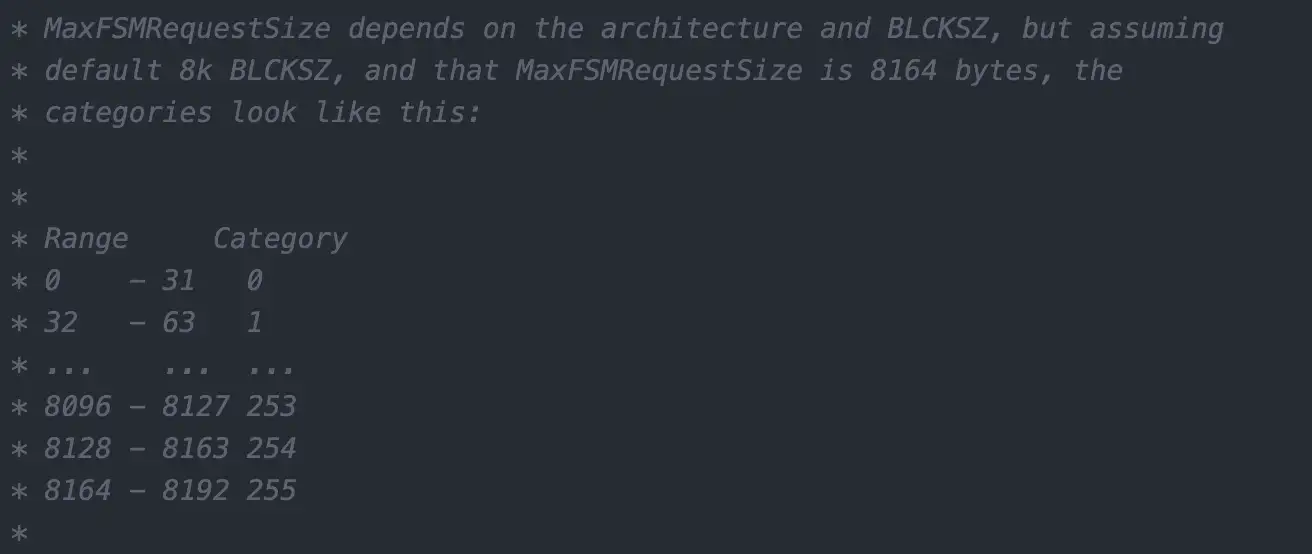
这样一个 8KB 的 page 的空闲空间大小,使用一个 uint8 类型就可以表示了,由 4 个字节变成了 1 个字节。
如果 page 大小超过了 8KB,例如是 32KB,那么步长也随之增加:32KB / 256
表示空闲空间的数据信息,存储到了在磁盘文件上,以 _fsm 结尾。文件的数据存储方式和 heap page 类似,也是采用了 page 的方式,page 的内部结构和前面提到的 heap page 类似,也有对应的 page header。
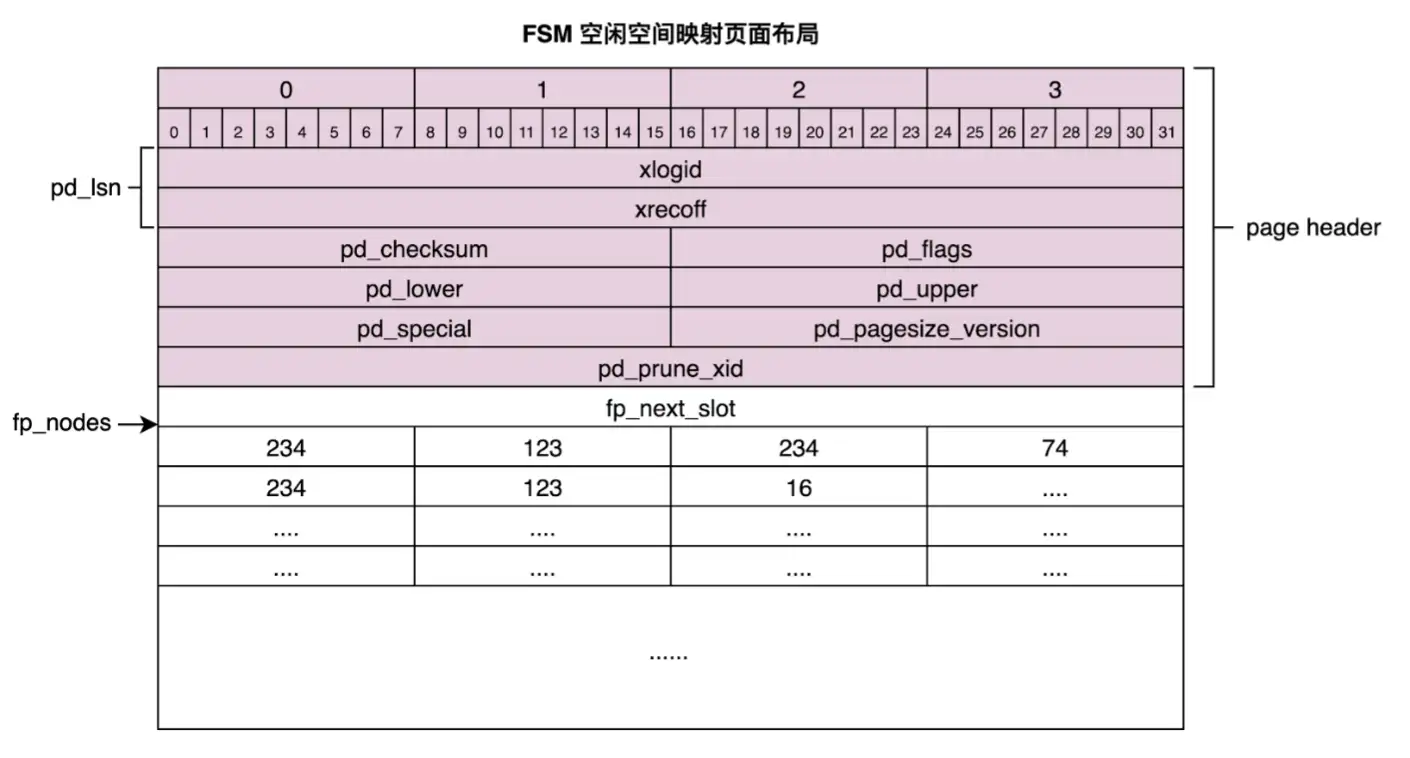
存储的内容则比 heap page 简单很多,主要是两个属性:
| |
- fp_next_slot:从堆中搜索的起始位置
- fp_nodes:空闲空间的数据(uint8 类型)
解决了空闲空间占用的问题,接下来就是空闲空间的数据如何组织的问题。其实这可以理解为是一个从无序的数组中,找到一个大于等于给定值的元素。
所以 Postgres 中使用了堆这个数据结构来存储空闲空间的大小,堆的叶子节点对应的是 page 的空闲大小,堆顶元素是最大的元素,当查找是,从堆顶元素进入,依次和其子节点进行对比,一直到达叶子节点。
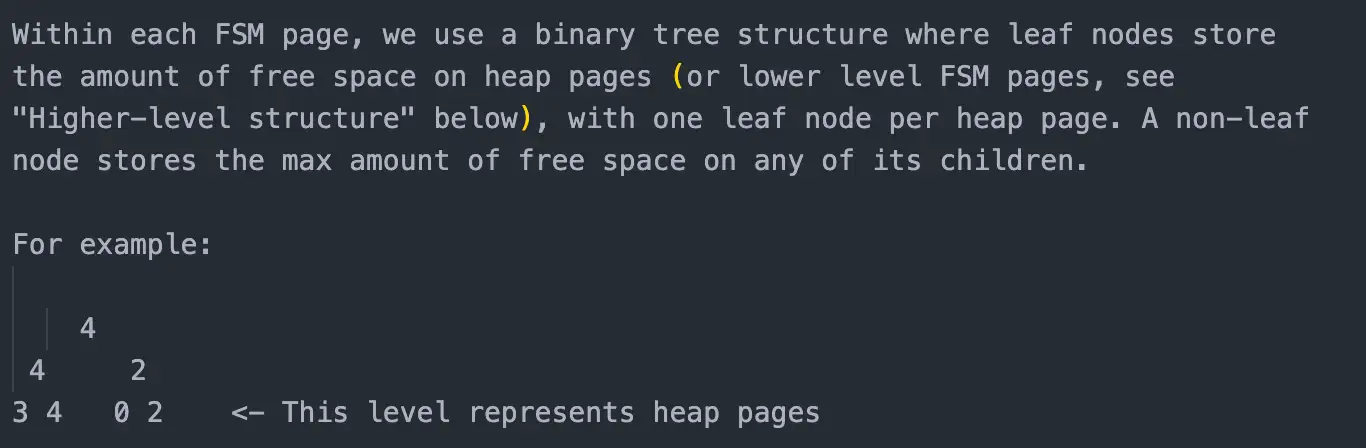
查找的时候,还需要注意一个问题,那就是如果每次都从堆的顶层节点进入,那么有可能不同的进程找到的 page 是一样的。
为了提升并发性能,让不同的进程尽量找到不同的 page,这样能够避免锁竞争。
所以在查找的时候,记录了一个下次开始查找的下标值,如果该下标处的值不满足条件,则跳转到其右边的那个节点,然后从右边的节点的父节点开始查找,以此类推。
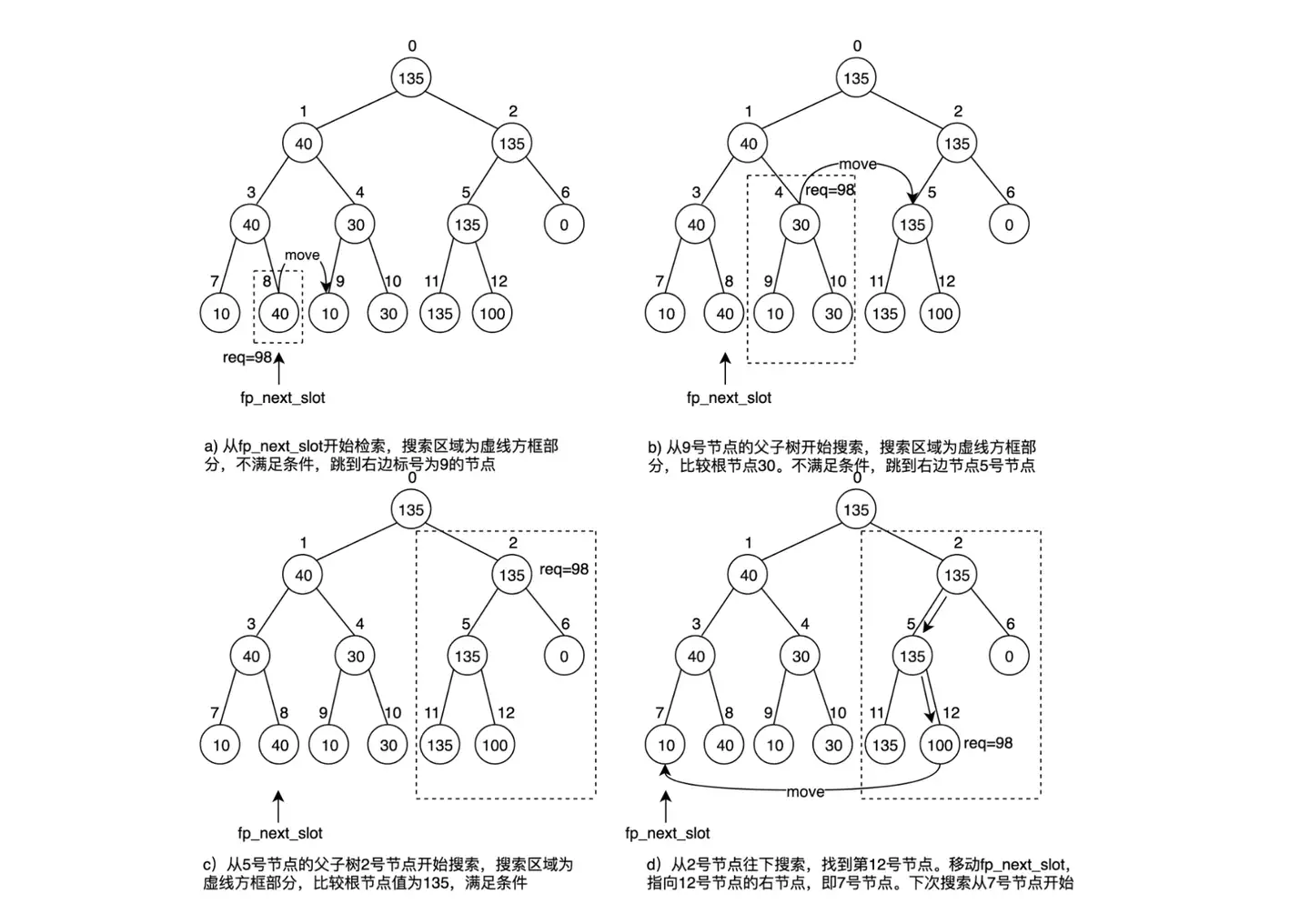
还需要注意一个问题,一个 FSMPage 有可能存不下所有的 heap page 的空闲空间大小。
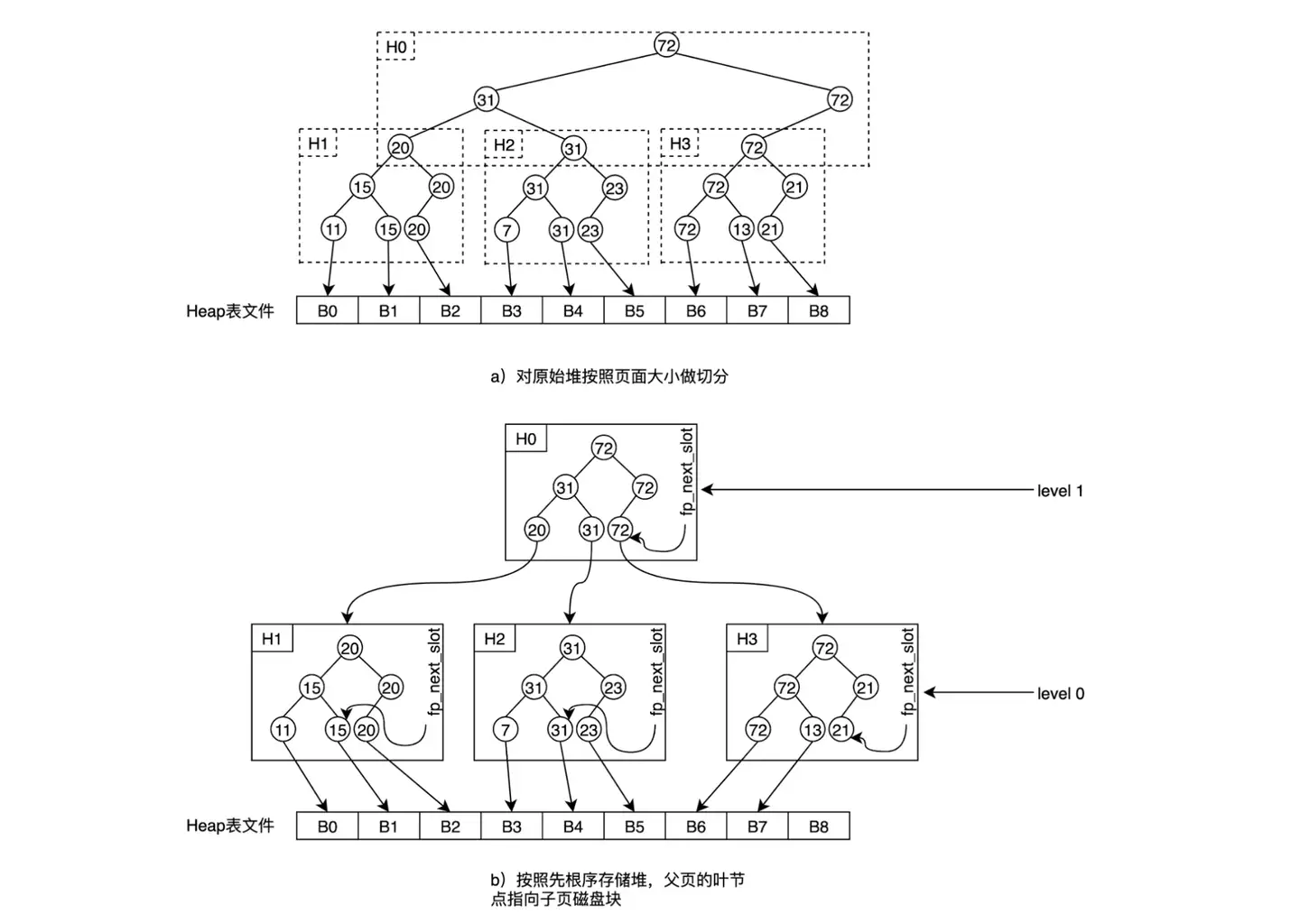
所以实际上在存储的时候,会将空闲空间大小存储到不同的 FSM Page 中,那么不同 fsm page 中的空闲空间数据,又怎么维护成一个堆结构呢?
实际上是使用了多层结构,将不同 fsm page 的数据维护成了多个 level 层级的关系。