在众望所归之下,前两天终于出了一个全新的课程《从零实现分布式 KV》,大家的学习热情都非常高涨,其中有很多同学都问到了一个共同的问题,那就是这个课程和我之前的《从零实现 KV 存储》有什么区别呢?
这一次就专门给大家解释一下。
其实说起来也比较简单,《从零实现 KV 存储》实现的是一个单机 KV 存储引擎,何为单机?一般指的是在一个 server 上的单个进程里运行的数据库,其主要解决的问题是数据如何存储到持久化存储介质中,比如最常见的磁盘。
所以我们会设计存储到磁盘上的数据会怎么进行组织,磁盘上的文件格式是什么样的,然后会考虑怎么才能够更加高效的从磁盘读取数据,减少磁盘 IO 次数。所以单机存储引擎更加专注于数据存储到磁盘的具体实现方法,并且要尽量保证数据不丢失。
常见的单机 KV 存储模型有 B+ 树、LSM 树、Bitcask,使用这些模型实现的单机 KV 引擎有 LevelDB、RocksDB、BoltDB、Badger、Pebble、RoseDB 等等。
那么《从零实现分布式 KV》 课程又实现的什么呢?
分布式 KV,其重点在于分布式。前面说到了,单机 KV 是在一个 server 上运行的,如果这个 server 出现了故障,或者磁盘损坏了导致了数据丢失等情况,那么这个数据库一是不能够响应用户的请求,二是存储在其中的数据有可能损坏,并且如果我们没有备份的话,数据就永远丢失了,会造成比较严重的后果。
所以分布式就能够比较好的解决这个问题,利用最朴素的思想,不要把鸡蛋放在同一个篮子里。既然数据存储在一个 server 上有非常大的问题,那么我们将数据拷贝出来,存储到不同的 server 上不就好了?
这样每个 server 上的一份数据一般叫做一个副本(Replica),如果一个 server 出现了故障,还有其他的数据副本可以继续使用。
但是数据有了多个副本之后,随之而来又带来了新的问题,那就是写数据的时候,应该写到哪个副本里面?还是全部的副本都写一遍?读数据的时候,应该从哪个副本去读?如果副本之间的数据不一致了怎么办?
等等,这些问题抽象出了一个新的概念,那就是共识,即让多个副本之间协调一致,统一对外提供服务,并且保证数据的完整一致性,我们需要一些手段来让多个副本之间达成共识,这一般称之为共识算法,常见的有 Paxos 和 Raft,而我们课程中实现的是 Raft 算法。

有了共识算法之后,我们可以在这个基础之上构建分布式、高可用的系统,而课程中实现的是最常见的分布式 KV 系统,每个 server 之上,都会使用 Raft 共识算法来保证多个副本之间的一致性,然后每个 server 本地都会维护一个存储数据的单机 KV,这个单机 KV 一般叫做状态机。
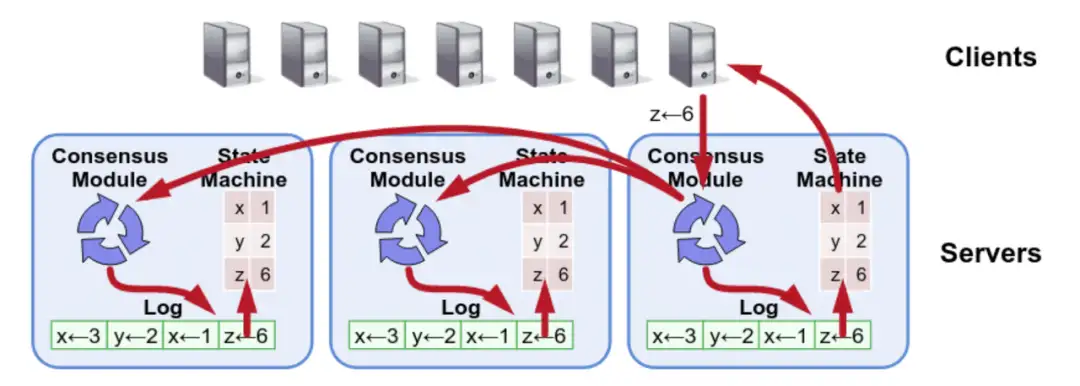
常见的分布式 KV 系统有 TiKV、ETCD、FoundationDB 等等。
所以现在大家应该就清楚了,分布式 KV 重点在于分布式算法,以及分布式系统的设计与实现,并且只是用到了单机 KV 来存储本地数据,而存储数据、磁盘数据组织的具体逻辑,是交给了单机 KV 去负责。
这两个课程的学习有先后顺序吗?
这也是问的比较多的问题,实际上并没有先后顺序,所以先学哪个都是可以的,也都能够学懂,彼此都是独立的内容。
最后,感谢大家的支持,希望这个课程能够对大家有所帮助,附上课程链接,想要购买者可查看:
《从零实现 KV 存储》
https://w02agegxg3.feishu.cn/docx/Ktp3dBGl9oHdbOxbjUWcGdSnn3g
《从零实现分布式 KV》
https://av6huf2e1k.feishu.cn/docx/JCssdlgF4oRADcxxLqncPpRCn5b